


Sie wollen aus dem Backend ein größeres Entitätsset abrufen? Stehen aber vor dem Problem dass sie laufend in eine Time Out geraten? Um hier Abhilfe zu schaffen gibt es die sogenannte Paging Funktion. Mit dieser ist es möglich größere Datenmengen für ein Request in kleinere Unter-Request zu packen und somit dem Time Out davon zu kommen.
Das beste ist: im Frontend müssen Sie gar nichts anpassen! Lediglich die Odata Implementierung müssen Sie leicht anpassen und der Rest funktioniert von alleine.

Wie funktioniert das ganze?
Zum einen legen wir einen Wert fest, welcher bestimmt wie viele Entitäts Einträge auf einmal ausgelesen werden sollen. Ein sogenannter Skiptoken. Dies hängt natürlich von der Größe ihrer Entität ab. In unserem Beispiel sollen immer 100 Einträge gleichzeitig zurück gegeben werden.
In unserer GET_ENTITYSET Methode werden nun immer maximal 100 Einträge zurück gegeben. Zusätzlich wird ein Positionsmarker, welcher quasi als Lesezeichen fungiert, mitgegeben. So werden im ersten Anlauf die Einträge 1-100 zurückgegeben, beim zweiten mal 101-200 und so weiter.
Im Frontend müssen wir hier nichts gesondert verarbeiten. Das Odata Model arbeitet hier automatisch. Sie stellen also ganz normal den Request, beispielsweise per oModel.read(…). Mit der ersten Antwort wird dem Model mitgeteilt das hier noch weitere Einträge folgen. Mit den letzten Einträgen aus der GET_ENTITYSET Methode wird ein Stop Kennzeichen mitgesendet, sodass das Model keine weiteren Daten erwartet. Für Sie im Frontend verhält sich das ganze wie ein Request.

Wie wird das ganze Implementiert?
Zunächst müssen Sie ein paar Einstellungen vornehmen, um die Funktionalität grundlegend zu aktivieren für ihren Odata Service.
Aktivieren des Soft-State
Diese Einstellung muss lediglich einmal für den OData Service vorgenommen werden. Egal wieviele Methoden später Paging implementieren sollen.
Im ersten Schritt redefinieren sie die DEFINE Methode in der *MPC_EXT Klasse ihres Odata Services.
Dort hinterlegen Sie folgenden Code:
method DEFINE. super->define( ). model->set_soft_state_enabled( abap_true ). endmethod.
Außerdem müssen Sie die beiden Methoden “/IWBEP/IF_MGW_SOST_SRV_RUNTIME~OPERATION_START” und “/IWBEP/IF_MGW_SOST_SRV_RUNTIME~OPERATION_END” aus der *DPC_EXT Klasse ihres Odata Services redefinieren. Bei diesen beiden Methoden müssen Sie keinen weiteren Code hinzufügen (Sie bleiben leer).
Auf ihrem Gateway müssen Sie nun den ICF Knoten für ihren Service bearbeiten. Hier zu rufen Sie die Transaktion SICF auf. Über den Baum finden Sie über folgenden Pfad “sap/opu/odata/sap/IhrService_srv” ihren Service.
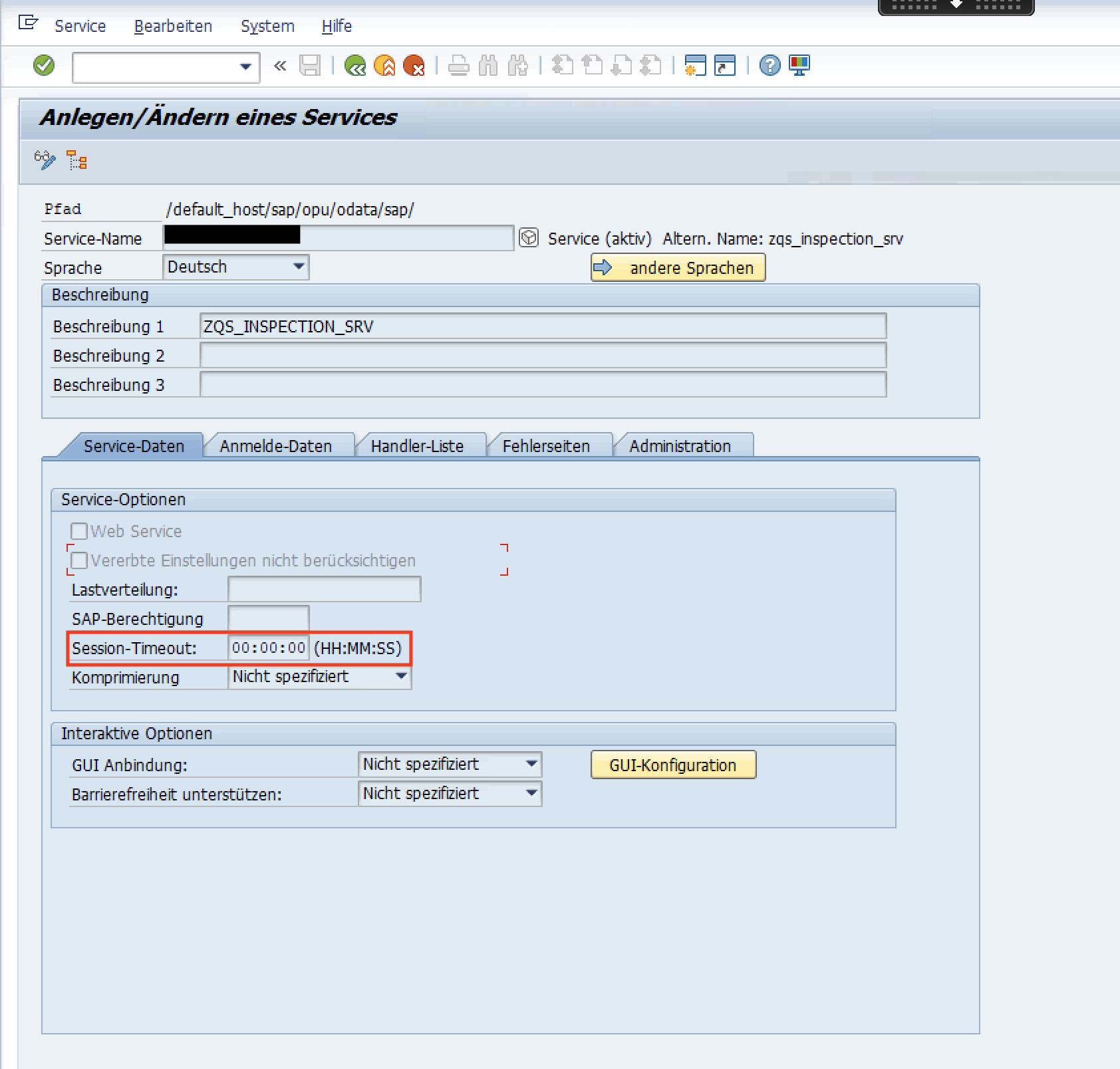
Im Reiter “Service Data” können Sie nun einen Session Timeout festlegen. Ein guter Wert hierfür wäre beispielsweise 00:30:00. Das bedeutet dass die Paging Session nach 30 Minuten abgebrochen würde. Haben Sie mehr Daten die Sie übertragen wollen, dann wählen Sie einen höheren Wert.
Anschließend wechseln Sie in die Transaktion /IWFND/MAINT_SERVICE hier laden Sie die Metadaten für ihren Service neu (Button oben rechts). Danach wählen Sie den Button Soft-State (rechts vom Metadaten Button) und bestätigen die Meldung. Im Ergebnis wechselt die “Soft-State” Spalte unten den Wert von Inaktiv zu Aktiv.
Das war es schon zur generellen Odata Service Anpassung. Diese müssen Sie nur einmal pro Odata Service ausführen.
Anpassung der GET_ENTITYSET Methode
Nun können wir damit loslegen die Get_Entityset Methode anzupassen!
Beim ersten Aufruf der GET_ENTITYSET Methode für eine Request müssen nun die Daten abgerufen werden. Anschließend werden sie in eine Klassenvariable geschrieben. So wird verhindert, dass die Ausleselogik für jeden Übertragungsblock erneut durchgeführt wird. Dafür wird eine Klassenvariable mt_entityset in der DPC_EXT angelegt. Sie hat den selben Datentyp wie das et_entityset Feld der GET_ENTITYSET Methode. Außerdem benötigen wir die Klassenvariable mv_delta_token, welche den Typ Timestamp hat.
An den Anfang der GET_ENTITYSET Methode wird zunächst folgender Code angefügt:
IF me->mt_entityset IS INITIAL. **Bisherige Datenselektion, anstatt in et_entityset in lt_entityset me->mt_entityset = lt_entityset. GET TIME STAMP FIELD me->mv_delta_token. ENDIF.
Nun haben wir unsere gewünschten Daten ausgelesen und können unsere Rückgabestruktur befüllen. Dazu müssen wir zunächst festlegen wie viele Einträge auf einmal zurück geben werden sollen. Hierzu wird im folgenden Abschnitt die Variable lv_chunk_size genutzt. Im diesem Beispiel möchten wir immer 100 Einträge zurück geben.
Zwei weitere Variablen definieren die Ober- und Untergrenzen zum auslesen der Daten. Die Untergrenze definiert ab dem wie vielten Eintrag von mt_entityset möchten wir Daten zurück liefern. Hierfür wird die Variable lv_old_skiptoken genutzt. Diese Variable ist in unserem Beispiel im ersten Durchlauf 0, anschließend 101, dann 202 und so weiter. Die Obergrenze (lv_skiptoken) berechnet sich aus der Summe von lv_old_skiptoken und lv_chunk_size.
Wenn diese Grenzen festgelegt sind müssen nur noch die entsprechenden Werte aus dem mt_entityset abgerufen und an die Rückgabetabelle angehängt werden. Das ganze sieht dann Beispielsweise so aus:
DESCRIBE TABLE me->mt_entityset LINES lv_table_size.lv_chunk_size = 100.lv_skiptoken = io_tech_request_context->get_skiptoken( ).lv_old_skiptoken = io_tech_request_context->get_skiptoken( ).IF lv_skiptoken IS INITIAL. lv_skiptoken = 0. lv_old_skiptoken = 0. ENDIF. IF CONV i( lv_skiptoken ) >= iv_table_size + 1.*Letzter Durchlauf -> Skiptoken leerenCLEAR es_response_context-skiptoken. ELSE.*Skiptoken um nächsten Block erhöhenlv_skiptoken = CONV i( lv_skiptoken ) + lv_chunk_size +1. es_response_context-skiptoken = lv_skiptoken. CONDENSE es_response_context-skiptoken. ENDIF.LOOP AT me->mt_entityset INTO ls_entity.IF sy-tabix < lv_old_skiptoken. CONTINUE. ENDIF. IF sy-tabix >= iv_skiptoken. EXIT. ENDIF. INSERT ls_entity INTO TABLE et_entityset. ENDLOOP.
Im Anschluss an das Paging soll die Klassenvariable mt_entityset und mv_delta_token auch wieder geleert werden. Dazu fügen Sie am Ende ihres Codes folgendes Snippet an:
IF es_response_context-skiptoken IS INITIAL.
es_response_context-deltatoken = me->mv_delta_token.
CLEAR: me->mt_entityset,
me->mv_delta_token.
ENDIF.
Zusammengesetzt könnte das ganze dann so aussehen:
IF me->mt_entityset IS INITIAL.********* Bisherige Daten Selektion******* me->mt_entityset = lt_entityset. GET TIME STAMP FIELD me->mv_delta_token. ENDIF.** Befüllen von et_entityset für einen DurchlaufDESCRIBE TABLE me->mt_entityset LINES lv_table_size.lv_chunk_size = 100.lv_skiptoken = io_tech_request_context->get_skiptoken( ).lv_old_skiptoken = io_tech_request_context->get_skiptoken( ).IF lv_skiptoken IS INITIAL.lv_skiptoken = 0.lv_old_skiptoken = 0. ENDIF.IF CONV i( lv_skiptoken ) >= iv_table_size + 1.CLEAR es_response_context-skiptoken. ELSE.*Skiptoken um nächsten Block erhöhenlv_skiptoken = CONV i( lv_skiptoken ) + lv_chunk_size +1. es_response_context-skiptoken = lv_skiptoken. CONDENSE es_response_context-skiptoken. ENDIF.LOOP AT me->mt_entityset INTO ls_entity.IF sy-tabix < lv_old_skiptoken. CONTINUE. ENDIF. IF sy-tabix >= iv_skiptoken. EXIT. ENDIF. INSERT ls_entity INTO TABLE et_entityset. ENDLOOP.** Letzter Durchlauf? Klassenvariablen löschenIF es_response_context-skiptoken IS INITIAL.es_response_context-deltatoken = me->mv_delta_token. CLEAR: me->mt_entityset, me->mv_delta_token. ENDIF.endmethod.
Zusammenfassung
So lässt sich schnell und einfach das Problem mit größeren Entitätsmengen lösen. Konnte ich damit ihr Problem lösen? Haben Sie noch Fragen zu dieser Anleitung? Oder haben Sie ein andere Problem bei der Entwicklung von Fiori Applikationen? Ich freue mich auf ihre Fragen!
Mit dem Manager Reporting Cockpit (Fiori&Web Dynpro) d. Überblick über Personal- und Zeitdaten Ihrer Mitarbeiter erhalten. Auch mobil die Kontrolle behalten
